
Lire un fichier en Python fait partie des compétences essentielles du développeur moderne, notamment lorsqu’il s’agit de manipuler des fichiers texte volumineux ou de gérer efficacement la mémoire. Que ce soit pour analyser des logs, traiter des données ou configurer des applications, la lecture fichier Python ligne par ligne s’impose comme une méthode fiable pour optimiser ces opérations. En s’appuyant sur des techniques éprouvées, il est possible de maîtriser la gestion de fichier en évitant les pièges liés à une consommation excessive de RAM ou à des erreurs de traitement.
Dans un contexte où les performances deviennent un enjeu crucial, notamment en 2025 avec l’augmentation continue des volumes de données, il faut privilégier des approches souples et robustes. L’usage du context manager with garantit une manipulation sécurisée des fichiers, assurant leur fermeture automatique sans intervention explicite. Par ailleurs, différentes méthodes telles que l’utilisation de la fonction readline(), l’itération directe avec la fonction open fichier Python, ou encore le réglage avancé du buffering lecture permettent d’adapter la lecture à des besoins variés et à des environnements contraints.
Ce guide détaillera ces méthodes avec des exemples pratiques et des conseils pour lire fichier ligne par ligne de manière efficace, tout en optimisant la performance lecture fichier. L’objectif est d’offrir un panorama complet et pragmatique afin de rendre ce savoir-faire accessible aux développeurs cherchant l’excellence dans la manipulation de fichiers texte Python.

Optimiser la lecture d’un fichier texte en Python avec l’itération lignes fichier
En Python, la manière la plus naturelle pour lire fichier ligne par ligne repose sur l’itération directe des objets fichiers ouverts. Cette technique combine simplicité et efficience, particulièrement adaptée aux fichiers volumineux où le chargement complet s’avère prohibitif. En appliquant une boucle for sur l’objet fichier obtenu via open fichier Python, chaque ligne est extraite à la demande, ce qui limite la charge mémoire.
Voici un exemple classique : with open('data.txt', 'r') as file:
for line in file:
print(line.strip())
Cette méthode profite du context manager with, garantissant que le fichier est automatiquement fermé à la fin de l’opération, un aspect crucial dans la gestion de fichier pour éviter les fuites de ressources. L’approche par itération est reconnue pour son équilibre entre performance lecture fichier et lisibilité du code, ce qui en fait un standard dans la communauté.
Quand privilégier readline() pour la lecture progressive de fichiers
La méthode readline() s’avère particulièrement pertinente pour un contrôle précis du processus de lecture. Contrairement à l’itération automatique, elle permet de manipuler explicitement chaque ligne lue, ce qui est utile dans les scénarios nécessitant une gestion conditionnelle ou un traitement intermédiaire entre les lectures.
Le code suivant illustre cet usage :
with open('data.txt', 'r') as file:
line = file.readline()
while line:
print(line.strip())
line = file.readline()
Ce procédé limite aussi la mémoire consommée, puisque seules les lignes actuelles sont en mémoire à chaque instant. Cette approche est idéale lorsque les fichiers ne peuvent être traités d’un seul bloc, et que l’on souhaite optimiser la optimisation lecture fichier pour répondre à des contraintes spécifiques d’environnement ou applicatives.
Techniques avancées pour améliorer la performance lecture fichier en Python
Au-delà des méthodes élémentaires, le réglage du buffering lecture est une option sophistiquée souvent sous-exploitée. En personnalisant la taille du buffer, Python permet d’ajuster la quantité de données chargées en mémoire à chaque opération de lecture, influençant directement la vitesse et l’impact mémoire.
Par exemple, open('data.txt', 'r', buffering=8192) augmente la taille du tampon à 8 Ko, ce qui peut améliorer significativement les performances sur certains supports de stockage ou systèmes d’exploitation. Dans des contextes de traitement intensif, cette technique participe à une optimisation lecture fichier notable, surtout quand on traite des données en continu ou des fichiers log complexes.
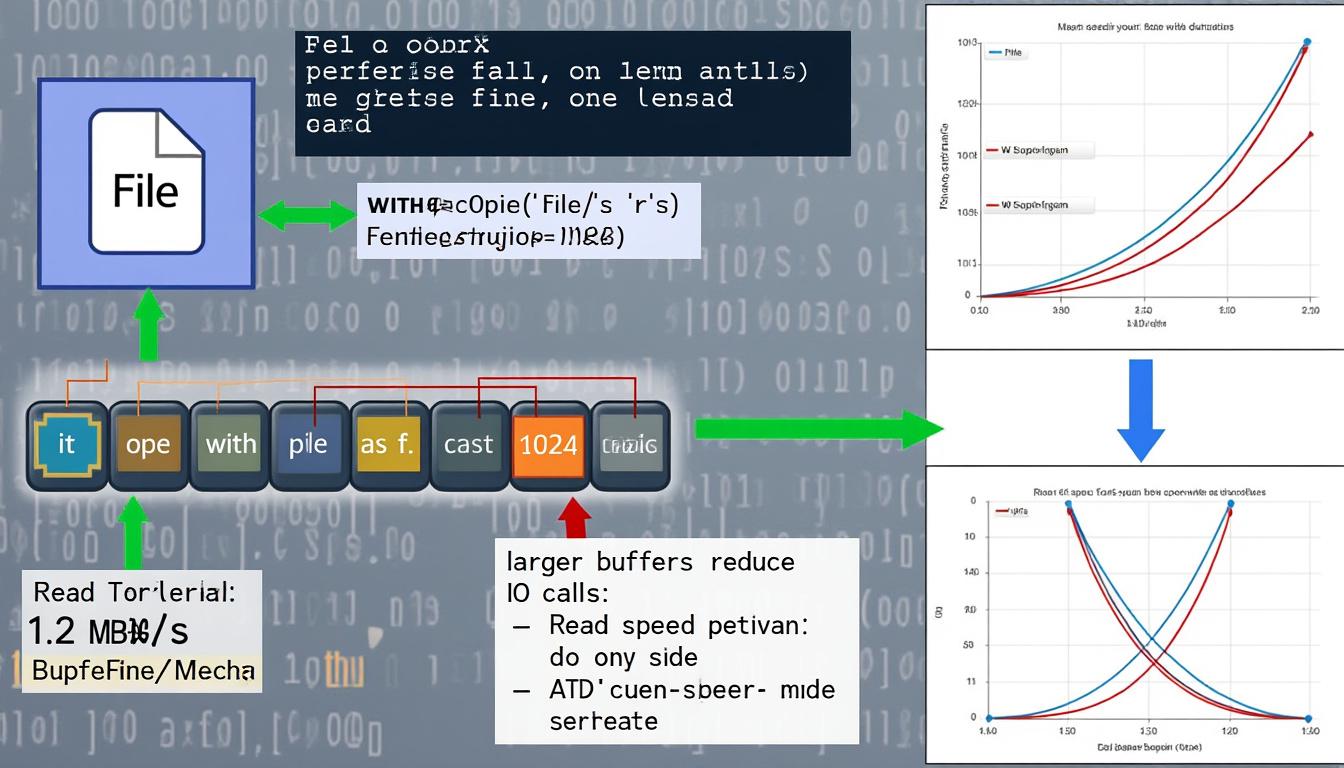
Par ailleurs, pour certains usages, la lecture intégrale via read() ou par segments contrôlés avec read(size) peut être envisagée, mais cette approche requiert une vigilance accrue pour ne pas saturer la mémoire, surtout pour les fichiers volumineux. Dans ce cas, privilégier l’itération ou readline reste la meilleure pratique pour maintenir un bon équilibre entre ressources système et vitesse.
Comment ouvrir un fichier en mode lecture en Python ?
Utilisez la fonction open() avec pour paramètre le chemin du fichier et le mode ‘r’ pour lecture, par exemple open(‘fichier.txt’, ‘r’).
Quelle est la différence entre read() et readline() ?
read() lit l’intégralité du contenu du fichier en une seule opération, tandis que readline() lit le fichier une ligne à la fois, ce qui est préférable pour les gros fichiers.
Pourquoi utiliser le context manager with pour la lecture de fichiers ?
Le context manager with assure la fermeture automatique du fichier après lecture, évitant ainsi les fuites de ressources et garantissant une meilleure gestion de fichier.
Comment gérer la lecture de très gros fichiers efficacement ?
Il est conseillé d’utiliser l’itération lignes fichier ou la méthode readline() qui permettent de ne pas charger tout le fichier en mémoire et d’optimiser la consommation mémoire.
Que signifie buffering en lecture de fichiers Python ?
Le buffering correspond à la taille du tampon mémoire utilisée lors de la lecture. Modifier ce paramètre peut améliorer la performance lecture fichier en adaptant la quantité de données chargées à chaque opération.