
La programmation concurrente en Python s’est largement démocratisée grâce à des bibliothèques robustes et accessibles. Au cœur de cette évolution, la gestion des threads avec le module concurrent.futures.ThreadPoolExecutor s’impose comme une solution efficace pour tirer parti de l’exécution parallèle des tâches. Cette technique améliore significativement les performances des applications où le multithreading est pertinent, notamment dans la gestion d’entrées/sorties ou l’exécution simultanée de fonctions indépendantes. Néanmoins, la maîtrise de ces outils réclame une compréhension claire des concepts de pool de threads, de synchronisation et surtout des limites de threads inhérentes à Python, dus notamment au Global Interpreter Lock (GIL) et aux capacités systèmes.
Maîtriser l’utilisation de ThreadPoolExecutor, c’est aussi savoir optimiser la concurrence pour éviter les surcharges, les blocages et assurer un fonctionnement fluide et fiable. Tout développeur soucieux d’améliorer ses solutions Python doit donc s’orienter vers une gestion méthodique des threads, équilibrant la parallélisation des tâches et les contraintes matérielles. Cet article se propose de détailler les mécanismes fondamentaux pour créer et gérer ces threads, en abordant la création des pools, la soumission des tâches, la récupération des résultats, et enfin, les bonnes pratiques pour contourner les points de blocage et optimiser les performances.
Ces notions concrètes s’adressent aux développeurs soucieux d’affiner leurs compétences en multithreading et en gestion des threads. La compréhension à la fois théorique et pratique de ThreadPoolExecutor constitue un levier indispensable pour exploiter pleinement les capacités de Python dans des contextes d’applications exigeants en performance et en réactivité.
En bref :
• ThreadPoolExecutor facilite la gestion simple et efficace des threads en Python.
• Le multithreading permet une meilleure utilisation des ressources pour les tâches I/O bound.
• Le GIL limite cependant l’exécution parallèle des threads sur les tâches CPU bound.
• La synchronisation des threads reste primordiale pour éviter les conflits et erreurs.
• Comprendre les limites des pools de threads évite les saturations et plantages.
Créer un pool de threads avec ThreadPoolExecutor pour une exécution parallèle en Python
ThreadPoolExecutor, issu du module concurrent.futures, fournit une API haut niveau pour gérer un pool fixe de threads. La création de ce pool permet de soumettre plusieurs tâches à exécuter simultanément sans se soucier de la gestion explicite des threads, simplifiant ainsi la conception concurrente. Par exemple, pour lancer dix tâches parallèles, il suffit d’instancier un ThreadPoolExecutor(max_workers=10), où max_workers détermine la taille maximale du pool.
Les tâches à exécuter sont ensuite soumises via la méthode submit(), qui retourne des objets Future représentant leur exécution asynchrone. Il devient alors possible d’interroger le résultat d’une tâche ou d’attendre sa complétion. Cette approche abstraite optimise la gestion des threads et prévient la complexité liée à leur cycle de vie.
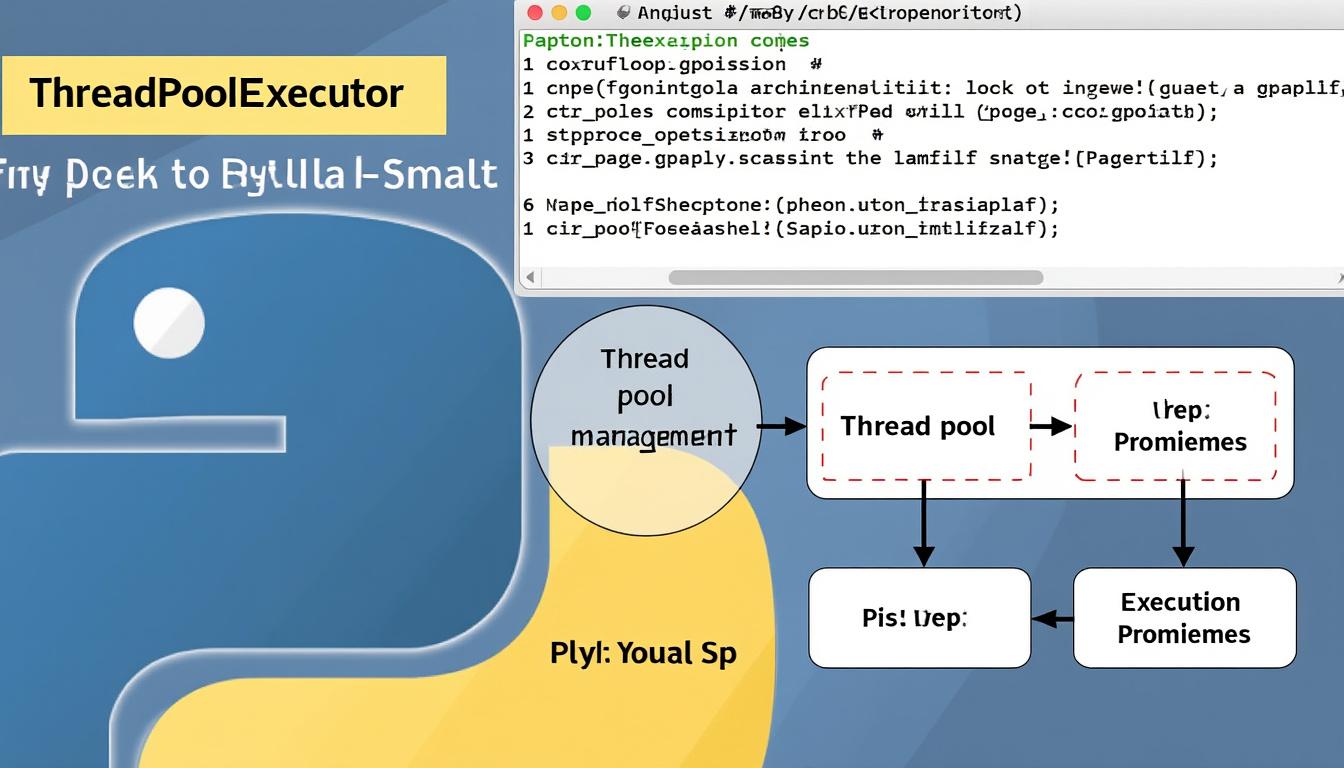
Optimiser la gestion des threads pour le multithreading en Python
Un aspect souvent sous-estimé est la gestion des ressources liées au thread. Le choix judicieux du nombre de threads dans un pool influence directement la performance et la stabilité. En effet, un nombre trop élevé peut entraîner une surcharge du système, une contention excessive sur les ressources partagées voire un blocage dû à la synchronisation.
À l’inverse, un pool trop restreint limite le bénéfice de l’exécution parallèle. Par conséquent, adapter la taille du pool en fonction du type de tâche — I/O bound ou CPU bound — et de la capacité matérielle est une étape stratégique pour tirer pleinement parti du multithreading. Le recours à des outils de synchronisation tels que time.sleep() peut aussi aider à réguler les conflits d’accès et la gestion des threads.
Les limites essentielles du multithreading en Python : comprendre le GIL et la gestion système
Le Global Interpreter Lock (GIL) est une contrainte majeure quand il s’agit d’exploiter le multitraitement en Python. Il empêche l’exécution concurrente de multiples threads dans une même instance de l’interpréteur Python, limitant donc l’exécution véritablement parallèle des threads CPU bound. Les threads doivent donc souvent attendre leur tour pour accéder au CPU, ce qui bride les performances dans certains scénarios.
Cependant, pour des tâches majoritairement axées sur les opérations I/O, la gestion des threads demeure ardente et profitable. Les applications réseau ou les interfaces utilisateurs bénéficient largement d’une telle architecture concurrente, à l’exemple des modèles client-serveur où simultanéité est recherchée.
Le module socket illustre notamment cette utilisation, en permettant à un serveur Python de gérer plusieurs connexions réseau via un pool de threads, sans se heurter aux limites imposées par le GIL sur la concurrence effective.
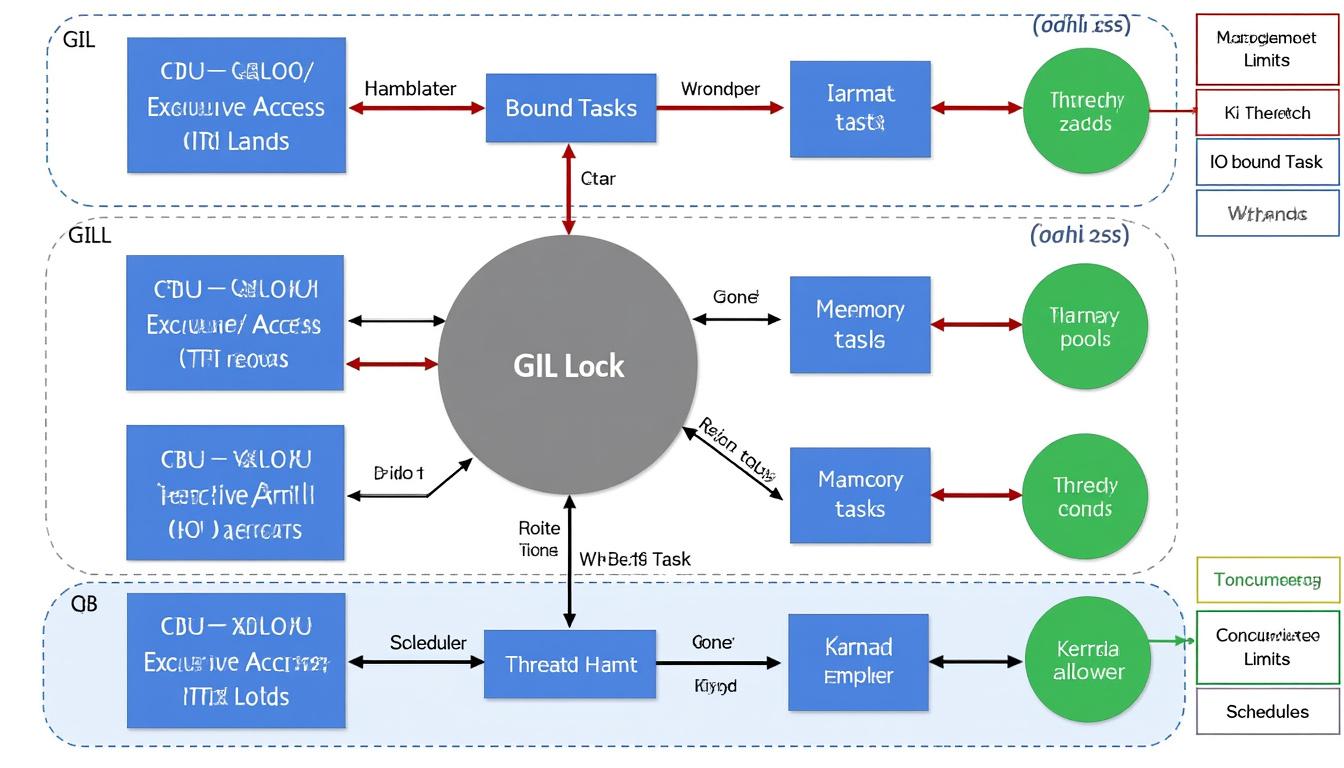
Bonnes pratiques pour éviter les pièges dans la gestion des threads et optimiser leur exploitation
Parmi les erreurs récurrentes, une mauvaise synchronisation provoque la corruption des données partagées ou des conflits d’exécution. L’usage de primitives de synchronisation telles que les verrous (locks), sémaphores, et événements, permet de contrôler l’accès concurrent aux ressources sensibles et garantit la cohérence du programme.
Autre point important, la surveillance des threads pour éviter les fuites mémoire, les deadlocks ou les threads zombies, nécessite une gestion rigoureuse du cycle de vie des tâches et de leur mise en veille. L’intégration de pauses calculées évite l’épuisement des ressources, procédant à une gestion fine des threads.
Enfin, un réglage adapté des pools permet de maximiser la performance sans risquer de surcharge. Cela passe aussi par une analyse du profil des tâches en termes de charge CPU et de dépendances. Les développeurs peuvent consulter des guides détaillés sur les commandes de base Python pour renforcer leur maîtrise des outils et fonctions indispensables à ce travail.

Quelle est la différence entre ThreadPoolExecutor et threading.Thread ?
ThreadPoolExecutor gère un pool fixe de threads et permet une soumission simplifiée des tâches, tandis que threading.Thread offre un contrôle plus fin mais nécessite de gérer manuellement chaque thread. ThreadPoolExecutor est recommandé pour les applications nécessitant la gestion de multiples tâches simultanées sans complexité supplémentaire.
Comment déterminer le nombre optimal de threads dans un ThreadPoolExecutor ?
Le nombre optimal dépend du type de tâches : pour des tâches I/O bound, un nombre élevé de threads peut être bénéfique, tandis que pour des tâches CPU bound, il est préférable de limiter ce nombre en fonction du nombre de cœurs CPU disponibles. Des tests empiriques et la surveillance de la charge système aident à ajuster ce paramètre.
Le multithreading permet-il toujours une vraie exécution parallèle en Python ?
À cause du GIL, les threads Python ne s’exécutent pas réellement en parallèle sur les tâches CPU bound. Toutefois, pour les opérations I/O bound, le multithreading améliore notablement la réactivité et la gestion simultanée des processus.
Quels outils utiliser pour synchroniser les threads ?
Les verrous (Lock), sémaphores, événements et autres primitives du module threading sont essentiels pour synchroniser les accès concurrents aux ressources partagées et éviter les conflits.
Peut-on associer ThreadPoolExecutor à des interfaces graphiques en Python ?
Oui, ThreadPoolExecutor peut être utilisé pour déléguer des tâches lourdes à un pool de threads afin de maintenir la réactivité d’une interface graphique. Des ressources comme celles disponibles sur l’interface graphique Python expliquent comment mettre en œuvre ce principe efficacement.