
La création d’un moteur de recherche interne performant en Python est une compétence de plus en plus prisée par les développeurs et les professionnels du référencement désireux d’optimiser la gestion de leurs contenus locaux. Ce projet rassemble plusieurs techniques fondamentales, allant du crawling par Scrapy à l’indexation sophistiquée, jusqu’au ranking intelligent grâce à des algorithmes avancés. S’appuyer sur des modules adaptés permet non seulement d’explorer efficacement une base de données documentaire, mais aussi d’améliorer la pertinence des résultats grâce à l’analyse textuelle et au traitement sémantique. Réaliser un moteur de recherche complet en interne, avec prise en compte des liens, pondération des documents et apprentissage, ouvre la voie à une meilleure exploitation des ressources, tout en garantissant un contrôle total sans dépendance extérieure.
Ce tutoriel illustre une approche pragmatique, alignée avec les besoins actuels du traitement automatique des informations. Il propose un déploiement progressif incluant la fouille locale des fichiers et pages web internes, la transformation des contenus en vecteurs exploitables via TF-IDF et Word2Vec, et la mise en place d’algorithmes de ranking combinant scores structurels et apprentissage supervisé. Cette méthode, parfaitement adaptée à un environnement Python, convient aussi bien pour des recherches documentaires classiques que pour des solutions plus avancées intégrant des modèles de machine learning. L’ensemble des étapes est conçu pour être reproductible et extensible, garantissant une optimisation continue des performances.
En bref :
– Mise en place d’un crawler local avec Scrapy pour extraction ciblée des liens internes.
– Nettoyage et indexation des contenus textuels avec PyIndex pour un traitement fiable.
– Usage combiné de TF-IDF, BM25 et Word2Vec pour une vectorisation sémantique adaptée.
– Intégration d’un moteur de ranking mêlant similarité cosinus, PageRank local et machine learning.
– Modularité et optimisation des performances par des bibliothèques Python spécialisées.
– Focus sur la pertinence des résultats via des signaux structurels et comportementaux.
Comment réaliser un crawler local efficace avec Scrapy pour un moteur de recherche en Python
La première étape dans la création d’un moteur de recherche interne est de collecter et d’organiser le contenu disponible à explorer. Le framework Scrapy s’impose comme un outil incontournable pour la fouille locale, capable d’extraire les liens internes et les documents web à indexer rapidement et proprement. En configurant un spider dédié, on peut cibler spécifiquement les balises <a> et <area>, ainsi qu’appliquer des filtres pour limiter la collecte aux domaines ou répertoires pertinents.
Cette démarche permet non seulement d’assembler un corpus cohérent et exhaustif, mais aussi de générer un export au format CSV compatible avec des outils de visualisation comme Gephi. Ce travail préalable facilite l’analyse du réseau interne de pages et la détection d’opportunités d’optimisation du maillage, cruciales pour le SEO local.
Il est essentiel d’ajuster certains paramètres du crawler : choisir un User-Agent approprié pour éviter les blocages, définir une politique de délai pour ne pas surcharger les serveurs même locaux, et prévoir un mécanisme pour éviter la réindexation inutile des pages inchangées grâce à des hash ou signatures. Cette rigueur garantit la robustesse du crawler et la fraîcheur des données.

Installation et configuration basique pour un spider Scrapy local
Pour débuter, il faut installer Scrapy via pip, créer un nouveau projet et configurer un spider ciblé. L’exemple suivant illustre les commandes principales :
- Préparer l’environnement :
pip install scrapy - Créer un projet :
scrapy startproject mon_moteur - Développer un spider ciblé dans le répertoire
spiders/, à configurer pour scanner les liens internes - Configurer l’export des URLs extraites vers un fichier CSV utilisable par Gephi
Ces éléments posent les bases d’un crawler local simple et performant, à personnaliser selon les spécificités du corpus et les objectifs métiers. Leur maîtrise est un atout pour la gestion des contenus et le référencement optimisé.
Indexation et analyse de texte robuste pour optimiser la pertinence des recherches internes
Une fois la collecte réalisée, la transformation des documents en données exploitables est une étape clé. Cette phase se concentre sur le nettoyage et la tokenization des contenus, indispensables pour le traitement des données dans un moteur interne. Le module PyIndex ou des solutions maison permettent notamment d’extraire le contenu textuel essentiel, supprimer les balises HTML inutiles, et appliquer une normalisation adaptée au français.
La tokenisation prépare le texte à l’analyse en décomposant les phrases en unités lexicales, tandis que la lemmatisation améliore la précision en ramenant les mots à leurs formes de base. Cela favorise la qualité de la base documentaire et, par extension, celle du moteur de recherche.
En procédant ainsi, il devient possible d’utiliser des méthodes éprouvées comme TF-IDF pour évaluer la pertinence des termes, puis d’évoluer vers des modèles plus complexes tels que Word2Vec pour une recherche sémantique avancée. Ces techniques, combinées à un algorithme de recherche efficace, contribuent à une expérience utilisateur optimale.
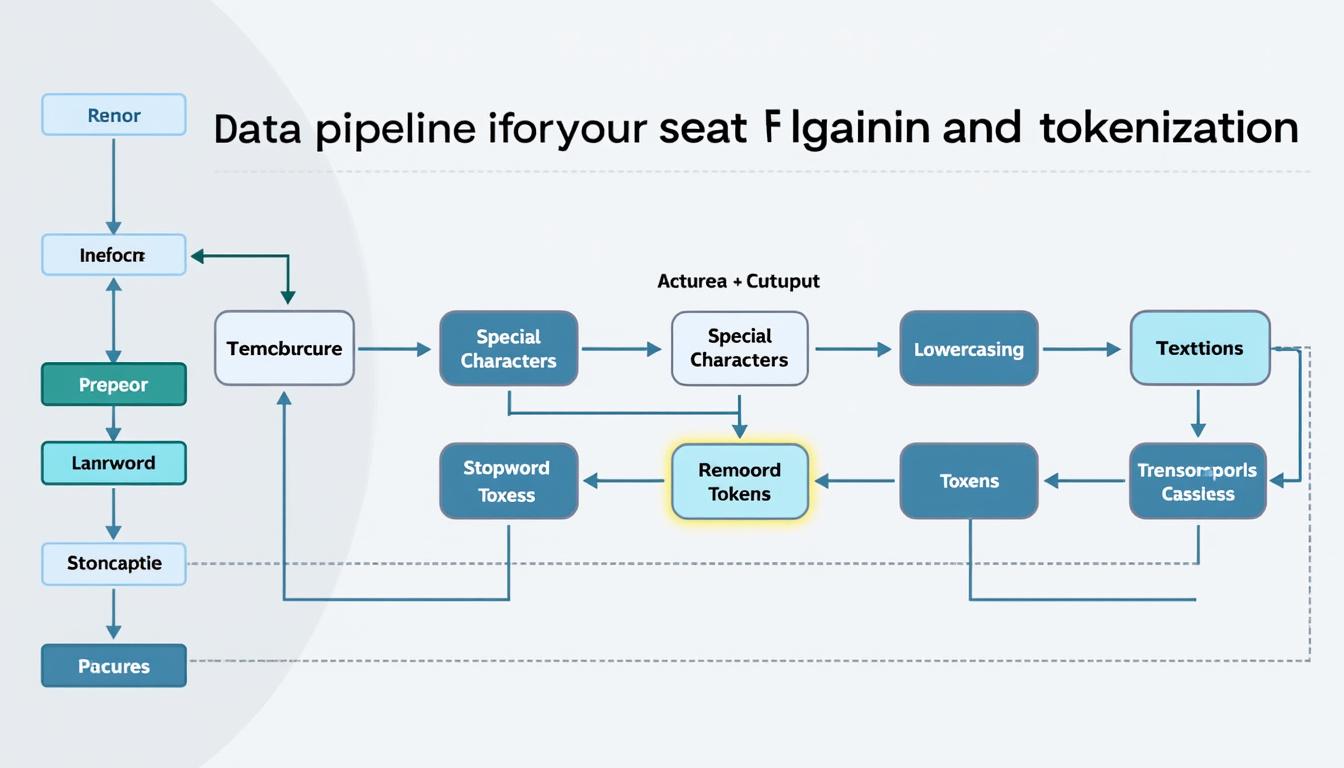
Quelques conseils pour une indexation fiable en Python
Le processus doit impérativement inclure :
- Suppression rigoureuse des balises HTML inutiles, notamment hors du contenu principal comme
<nav>ou<footer> - Extraction ciblée des balises
<title>et<main>pour maximiser la pertinence - Tokenization adaptée au français pour gérer les élisions et conjugaisons
- Lemmatisation ou stemming pour homogénéiser les formes lexicales
Le respect de ces étapes garantit une indexation qualitative, base sans faille pour la recherche textuelle. Dans ce contexte, l’optimisation continue du moteur s’appuie aussi sur l’analyse précise des scores produits, parmi lesquels on retrouve notamment le BM25, un algorithme supérieur à TF-IDF en production pour ajuster la pondération des documents selon leur longueur.
Classement pertinent des résultats avec algorithmes avancés et apprentissage automatique
Le scoring et le classement des résultats constituent la dernière étape majeure dans la construction d’un moteur de recherche interne. Ici, différentes composantes interviennent pour améliorer la qualité des classements :
- Scoring vectoriel par similarité cosinus sur les vecteurs issus de TF-IDF ou Word2Vec
- Pondération avec BM25 afin d’intégrer la longueur des documents
- Intégration du PageRank local des pages, calculé via PyScan, pour refléter l’autorité au sein du corpus
- Application de modèles Learning to Rank pour ajuster le classement selon les interactions utilisateurs et autres signaux comportementaux
Cette approche hybride permet de dépasser les limites des simples algorithmes basés sur le texte, en combinant des signaux structurels et sémantiques. Le résultat est un moteur optimisé qui s’adapte et s’améliore au fil du temps, garantissant la découverte des contenus les plus pertinents en priorité.
La mise en œuvre peut s’appuyer sur des bibliothèques comme XGBoost pour entraîner des modèles légers adaptés au contexte local, garantissant une amélioration rapide des résultats et une bonne gestion des ressources informatiques.
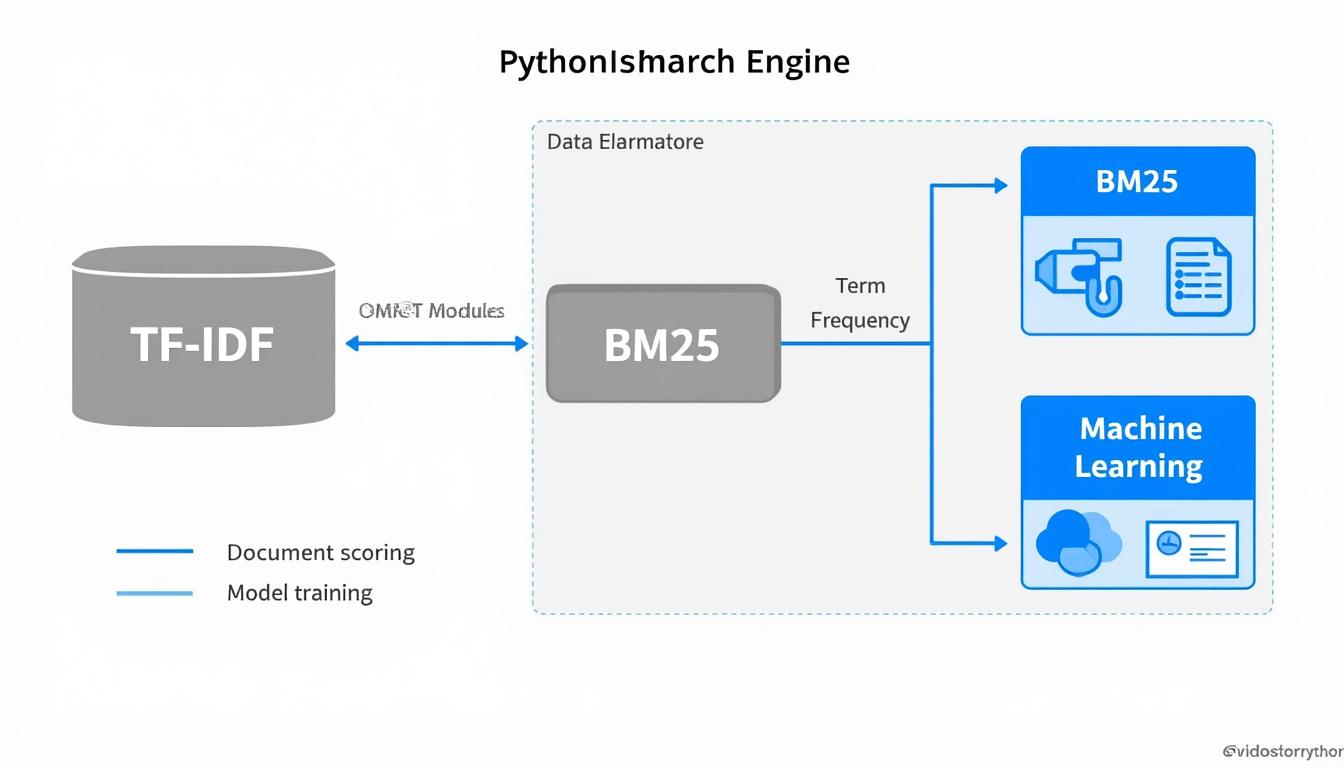
Pour approfondir ce sujet, notamment en matière d’optimisation SEO liée à la structure des données et à la qualité du netlinking, il est recommandé de consulter l’article suivant : comment optimiser un maillage interne efficacement. De même, les enjeux de l’intention de recherche en SEO vus à travers le prisme du traitement et de l’analyse textuelle sont détaillés sur : l’intention de recherche SEO.
Quelles bibliothèques Python sont essentielles pour créer un moteur de recherche interne ?
Scrapy pour le crawling, PyIndex pour l’indexation, et des outils comme gensim pour la vectorisation sémantique sont les principales bibliothèques recommandées.
Comment optimiser la pertinence des résultats dans un moteur de recherche local ?
L’utilisation combinée de TF-IDF, BM25, PageRank local et des modèles Learning to Rank permet d’améliorer significativement la précision des résultats.
Peut-on intégrer du machine learning dans un moteur de recherche interne développé en Python ?
Oui, grâce à des bibliothèques comme XGBoost, il est possible d’appliquer des modèles d’apprentissage supervisé pour ajuster le classement en fonction des interactions utilisateurs.
Pourquoi utiliser un crawler local pour construire un moteur de recherche ?
Le crawling local permet de constituer un corpus exhaustif et contrôlé, indépendant des contraintes et limites liées au scraping de sites externes.
Comment gérer la mise à jour de l’index dans un moteur de recherche interne ?
En utilisant des signatures ou hash des pages, il est possible de détecter les modifications et d’indexer uniquement les contenus mis à jour, ce qui optimise les performances.