
Dans un univers numérique où chaque seconde compte, la capacité à automatiser la collecte et le traitement des données web devient un atout indispensable. La création d’un scraper Python, d’un bot Python ou d’un automate Python permet de simplifier des tâches répétitives, d’extraire des informations précieuses à grande échelle, et d’intégrer ces données dans des flux de travail optimisés. Avec le volume colossal d’information disponible sur internet en 2026, maîtriser les techniques avancées de web scraping en Python est devenu essentiel pour les professionnels du SEO, les analystes de données, et les développeurs cherchant à concevoir des solutions fiables, performantes et respectueuses des règles légales.
Le web repose sur une multitude de pages HTML structurées par des balises spécifiques. Un scraper analyse ce code source, identifie les données pertinentes grâce au parsing HTML, et les extrait pour un usage ultérieur. Grâce à l’écosystème riche de Python, des bibliothèques telles que BeautifulSoup, Requests Python ou Selenium facilitent cette extraction, chacun apportant ses qualités distinctes : simplicité, interaction avec du contenu dynamique ou traitement asynchrone. Ce tutoriel détaillé propose un cheminement méthodique pour concevoir un outil d’automatisation adapté à chaque besoin, qu’il soit la surveillance de prix, la récupération ciblée de contenus, ou la réalisation de tests automatisés sur des interfaces web.

Au-delà des aspects techniques, il est primordial de comprendre le cadre légal et les limites à ne pas franchir lors du scraping. L’utilisation respectueuse des fichiers robots.txt et la préférence pour les API Python quand elles sont disponibles assurent la conformité et la pérennité des projets. Cette introduction s’adresse aux développeurs souhaitant maîtriser les fondements solides pour créer un scraper ou un bot Python efficace, performant, et fiable, à la fois pour leurs projets personnels et professionnels.
En 2026, construire son propre automate Python n’est plus réservé aux experts : la richesse des outils et la clarté des méthodologies font de cette compétence un passage obligé vers une efficacité décuplée dans le traitement de données numériques.
Pourquoi choisir Python pour créer un scraper, un bot ou un automate Python performant ?
Python s’est imposé comme un langage de référence dans le domaine de l’automatisation et du web scraping en raison de sa simplicité syntaxique, sa polyvalence et l’abondance de ses bibliothèques spécialisées. Face aux changements fréquents de la structure des sites web, la flexibilité du langage permet une adaptation rapide du code. Cette propriété est cruciale puisque toute modification du design ou de la structure HTML d’une page peut rendre obsolète un scraper, exigeant un ajustement aisé et rapide.
Outre cette adaptabilité, Python s’excelle dans la manipulation de contenus textuels et d’appels réseaux, deux piliers du scraping. Son intégration fluide avec des bibliothèques comme Requests Python pour effectuer des requêtes HTTP, ou BeautifulSoup pour le parsing HTML simplifie la construction et la maintenance des scripts. Pour les sites générant dynamiquement du contenu via JavaScript, l’utilisation combinée de Selenium autorise la gestion de ces interactions complexes.
Enfin, la communauté Python très active garantit un support continu avec de la documentation mise à jour, des projets open source robustes, et une diversité d’outils couvrant de multiples besoins : extraction, stockage, analyse et automatisation. Ce réseau d’expertise s’avère précieux pour mener des projets professionnels ambitieux avec un haut niveau de fiabilité.

Comprendre le fonctionnement d’un scraper web avec Python
Le principe fondamental d’un scraper consiste à analyser le code source HTML d’une page web, repérer des balises spécifiques correspondant aux données souhaitées, et les extraire automatiquement. Par exemple, dans un site de vente en ligne, le scraper identifiera la structure HTML qui contient les détails du produit et ses tarifs, souvent organisés via des classes CSS facilement ciblables.
Typiquement, la démarche suit ces étapes : envoi d’une requête au serveur via HTTP, récupération de la page HTML, parsing du contenu avec des outils adaptés, extraction des données ciblées, et enfin stockage ou traitement de ces informations. Avec Python, cette pipeline est homogène et flexible grâce aux bibliothèques standards et permet d’automatiser l’ensemble du processus.
Cependant, le scraping nécessite une attention particulière à la gestion des erreurs, notamment avec des sites dont le HTML est complexe ou modifié fréquemment. Des mécanismes de contrôle et de gestion des exceptions sont donc indispensables pour assurer la robustesse d’un automate.
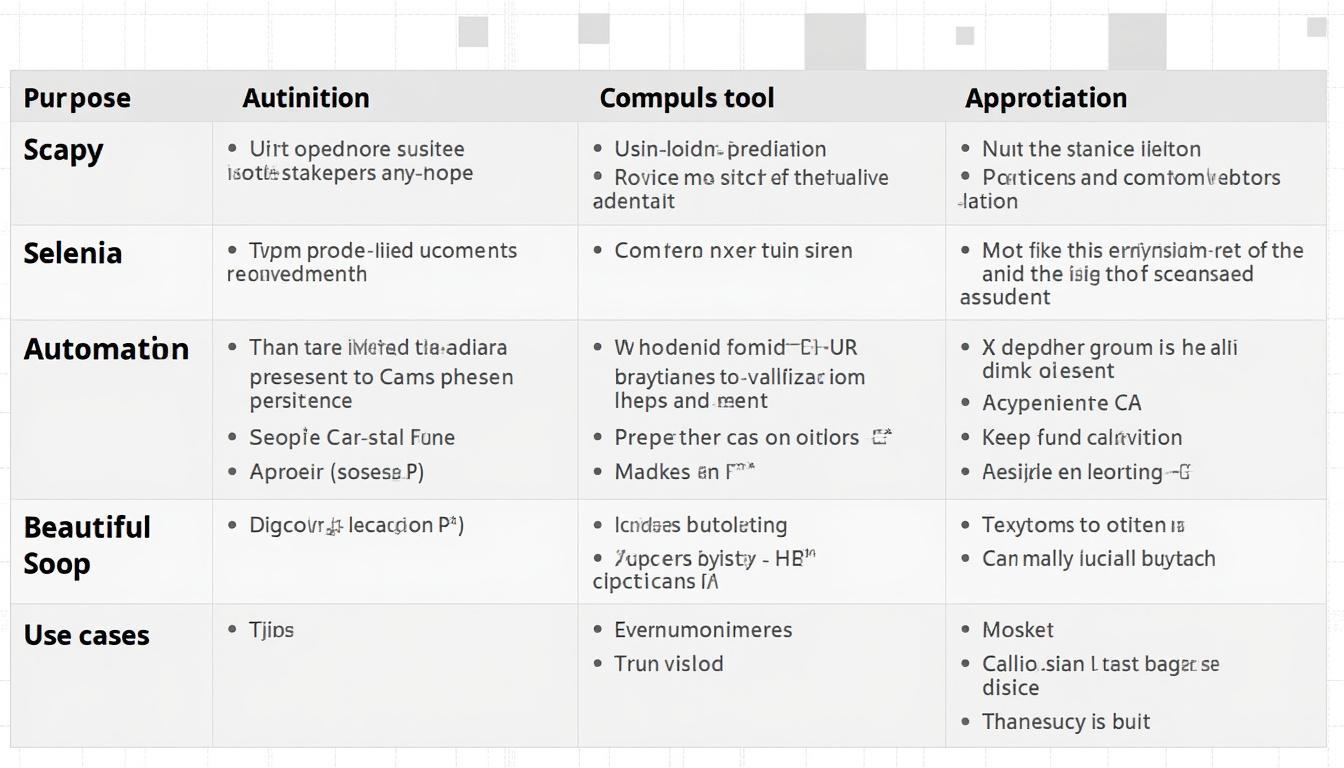
Les meilleures bibliothèques Python pour développer un scraper, un bot ou un automate fiable
Trois outils majeurs occupent une place centrale dans le développement de projets d’automatisation web en Python :
Scrapy se distingue comme une plateforme robuste, particulièrement adaptée aux projets nécessitant un scraping à grande échelle. Son architecture orientée objet facilite la gestion de spiders – des agents de scraping dédiés à un site ou un type de page. Scrapy offre des capacités asynchrones, augmentant significativement la rapidité d’exécution sur des volumes importants de pages.
Selenium, quant à lui, agit en simulant un navigateur complet permettant d’interagir avec des pages dynamiques. Cela ouvre la porte à des automatismes plus complexes, capables de gérer du contenu généré via Javascript, les clics, et les formulaires. Malgré une approche plus lourde, il s’intègre parfaitement avec d’autres outils pour un parsing précis ultérieur.
Enfin, BeautifulSoup reste un pilier incontournable pour un développement rapide et ciblé de scrapers. Sa simplicité en fait l’outil idéal pour des scripts modulaires simples orientés vers l’extraction de données dans des documents HTML statiques, avec une grande tolérance face aux erreurs de balisage.
Développer un scraper Python simple avec BeautifulSoup : mise en pratique étape par étape
Pour illustrer l’utilisation pratique d’un scraper Python, l’exemple contenu dans ce tutoriel cible un site test dédié au scraping : Quotes to Scrape. Cette plateforme est parfaite pour découvrir les mécanismes d’extraction sans contraintes légales ou techniques.
Le script commence par effectuer une requête HTTP avec la bibliothèque requests, puis analyse et transforme la page HTML à l’aide de BeautifulSoup. Les balises contenant les citations et leurs auteurs sont extraites grâce à la recherche par classes CSS. Enfin, les données obtenues sont enregistrées dans un fichier CSV, prêt à être exploité.
Ce processus met en lumière les avantages du parsing HTML : simplicité, rapidité et précision. Il s’agit d’un challenge pédagogique incontournable pour maîtriser la programmation d’un automate Python dédié au scraping.
Risques et limites techniques du web scraping en 2026 : législation et bonnes pratiques
Bien que la puissance du scraping soit indéniable, entreprendre la collecte automatique de données web soulève un certain nombre de contraintes légales et techniques. La visite automatisée de sites, notamment en grand nombre ou à haute fréquence, peut violer les conditions d’utilisation des plateformes. En 2026, respecter les directives du fichier robots.txt demeure une première règle de bon sens, quoique non contraignante juridiquement.
Au-delà, le respect des droits d’auteur et de la protection des données personnelles est impératif. Le scraping d’informations sensibles ou identifiables sans consentement est strictement interdit, et s’accompagne de sanctions financières sévères. Ainsi, la priorité donnée à l’utilisation d’API Python de données officielles reste une précaution majeure dans la conception d’un scraper.
D’un point de vue technologique, les sites mettent de plus en plus en œuvre des dispositifs anti-scraping, tels que la limitation du débit ou le blocage d’IP, rendant nécessaire l’usage d’outils avancés et d’un environnement technique robuste pour maintenir la continuité de l’automatisation.
Comment débuter avec un scraper Python ?
Il est conseillé de commencer par un projet simple utilisant BeautifulSoup et requests Python, afin de se familiariser avec le parsing HTML et l’envoi de requêtes HTTP.
Quelle bibliothèque choisir pour scraper des sites avec contenu dynamique ?
Selenium est le choix recommandé lorsqu’il s’agit de gérer des sites web gérés par JavaScript, car il simule un navigateur réel et permet d’interagir avec la page.
Quels sont les risques juridiques liés au web scraping ?
Le scraping peut enfreindre les conditions d’utilisation des sites, violer les droits d’auteur ou la protection des données personnelles, entraînant des sanctions si les règles ne sont pas respectées.
Quelle est l’alternative au web scraping pour récupérer des données ?
Les API Python proposées par les sites restent la méthode la plus sécurisée et fiable pour accéder aux données sans violer les règles d’usage.
Comment gérer l’évolutivité d’un scraper Python ?
L’utilisation d’outils comme Scrapy avec ses capacités asynchrones permet de gérer efficacement un grand volume de pages et d’assurer la robustesse du scraper dans le temps.